Big Data and Advanced Analytics Architecture on AWS and Azure

No matter if you belong to a ‘Small and Medium-sized Enterprise’, a ‘Multi-National Corporation’ or a ‘Start-up’, every business is looking to get a piece of “cloud” in their technology stack. It is simply understandable, the flexibility to scale on click of a button, highly available services for the customers or the luxury to manage the costs on a pay-as-you-go basis are game changers.
One of the most frequently asked question is “which cloud provider should I choose?” The answer to this is not a simple one. The leading public cloud providers like Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform (GCP) offer a broad set of services with global reach and are massively investing in innovating their services and competing closely with each other. In my opinion, the benefit of this competition is the significant pace at which cloud services are evolving.
This article gives a brief overview of the available services between Amazon Web Services and Microsoft Azure within the Big Data and Advanced Analytics space. If you are planning to Modernize your Data and Advanced Analytics use-cases on either one of the providers, it gives you a high-level understanding of how your target architecture will look like.
This article is not intended to help you choose a public cloud services provider but to give an overview of which services can be used together to solve Big Data and Advanced Analytics challenges.
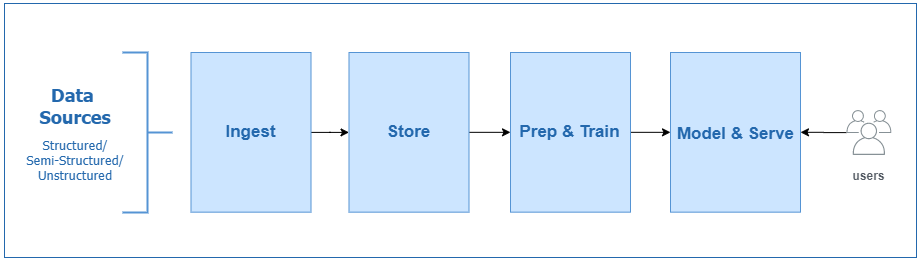
There are four main components in the data flow of this architecture and each one of them is discussed below:
Ingest:
It is about collection of data from heterogeneous sources and its ingestion into a centralized data store. This data store is typically an object storage, which is capable of storing different types of data i.e. structured, unstructured or semi-structured data (database tables, logs, media, files). The process of data ingestion can differ based on the type of data sources and the frequency at which data is produced. There are two main types of ingestion. Either on regular intervals (in the form of batches) or continuously as streaming data.
In the batch ingestion mode, the data is ingested in the form of files such as extraction of data from database tables. Data can be ingested using third party applications, data pipeline and orchestration tools.
Whereas, in the streaming ingestion mode, data is continuously ingested in the form of streams via data collectors. A data collector could be any web, mobile or a custom application that sends data to a streaming store in real-time. A streaming store, on the other hand accepts the data, and store it for further processing.
During the ingestion process, one approach is to perform basic transformation on the input data before storing it to the target data store. These transformations could be metadata extraction, schema creation or simple data enrichment. A quick approach is to store the input data into a staging area first, perform data transformations, and then move the data in the target data store.
Storage:
The next step in the architecture design is the storage of your data sets. The selection of an appropriate data store, being a very important architecture decision, depends on which type of data file formats you foresee to store and process. Mostly, an object store is a suitable candidate since it can store many different types of data and can fulfill the scalability requirements in the future as well. Going a step deeper, the storage part has two components i.e. Schema in which data will be stored and a Metadata Catalog, which stores the information about the data in the data store.
In the Big Data and Advanced Analytics space, the schema definition part refers to the creation of a schema based on a Data Lake design, which not only support many efficient open source file storage formats (discussed below) but also provide distributed querying tools such as Presto, HIVE, Impala and Spark SQL to query data using SQL-like query language. One of the benefits is the ease of creating tables using the “schema-on-read” functionality after loading the data in the data store.
The metadata catalog is the centralized schema repository, which contains metadata information about all the data files stored and is available for access to all the query engines.
Our business systems and applications are generating data every hour, minute and second. In no time, it usually becomes a bottleneck to process hundreds of thousands of data files. To improve the performance of data processing, there are some commonly used open source files formats i.e. ORC, Parquet and Avro. One added benefit of these formats is that they also compress quite efficiently with compression techniques like Snappy and GZip, and can save significant storage costs.
ORC and Parquet are column-based file formats while Avro is row based. If your use case retrieves all or some fields in a row for each query, Avro would be the choice. However, if you have many columns in your dataset but you mostly use a subset of those for your queries, then ORC or Parquet are a better choice since these are optimized for such use cases. Apart from the above-mentioned formats, CSV and JSON are also commonly used.
Prep and Train:
Once the data is stored in the data store, it is time to use it for solving business problems. This component provide its intended users, a platform to use the data for interactive data exploration and preparation techniques. After the preparation phase, the data is used to train, generate machine-learning models, and derive deeper insights on the defined business use-cases.
For the data exploration and preparation part, the users (usually statisticians and data scientists) require specific tools to work in an iterative way to explore and evaluate the usefulness of their data sets. These tools help the users to quickly understand the datasets, query large amount of data and visualize the results based on charts and graphs. As a result, data is transformed and enriched to be used for training and modeling purposes.
Other Big Data and Advanced Analytics use-cases could be to process huge amounts of streaming data, run ad-hoc queries or analyze raw data sets to perform root cause determination.
Model and Serve:
The last component in this architecture mainly acts as a serving layer where the analyzed data is stored into a Data Warehouse or to a Data Analytics services and the end-users can consume them to build custom reports. This data could be in the form of predictions based on the machine-learning models or in a structured form for analytical reporting based on business intelligence use-cases.
Tools like high performance databases, data warehouse and visualization applications are usually part of this component.
Moving forward, let us discuss how this architecture will look like with Microsoft Azure services. A brief discussion on each component of the architecture is below.
Proposed implementation on Azure
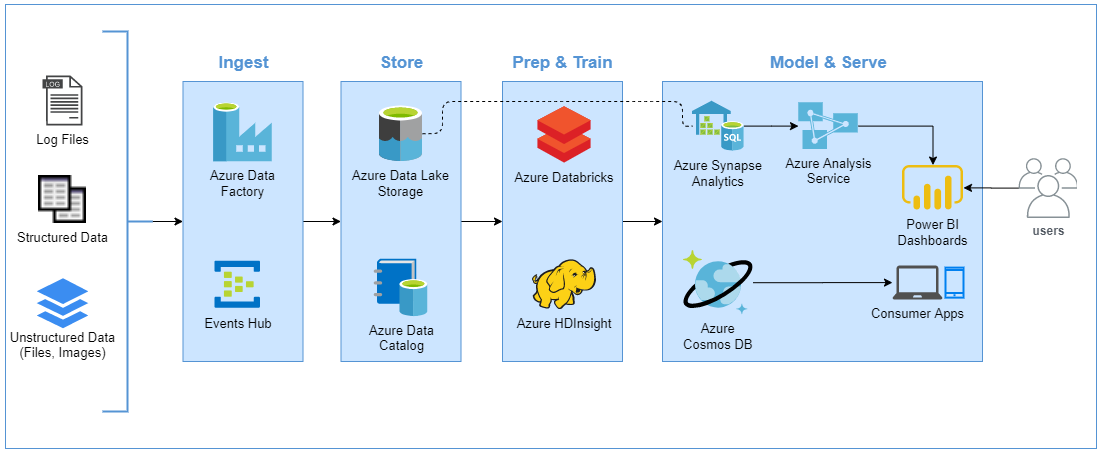
Ingest: In the first component, the data is ingested using one of my favorite Azure services for ingestion and orchestration, that is Azure Data Factory. The Azure Data Factory is a cloud based ETL tool for data integration and transformation. For streaming data ingestion, Azure Events Hub service is used to build real-time data pipelines. It can stream millions of events per second from any source and seamlessly integrate with other Azure data services.
Store: For storage, Azure Data Lake Storage is the ideal candidate to provide a secure and massively scalable data store for all kinds of data sets with capabilities dedicated to big data analytics. Whereas, the Data Catalog service is used to create a metadata catalog which stores information about business, technical and operational metadata and helps simplifying data asset discovery.
Prep & Train: For data preparation and training, both Azure HDInsight and Azure Databricks provide capabilities to not only clean, transform and enrich unstructured datasets but also apply machine learning techniques for building and training models and get deeper data insights. The users can create in-built notebooks with support of programming languages i.e. Scala, Python or R.
Model & Serve: The results of data processing are then stored in the data warehouse and analytics applications such as Azure Synapse Analytics to be used by Power BI reports and dashboards generated by the user. While the insights gained from machine-learning models are moved to Azure Cosmos DB for access through consumer applications.
On the contrary, let us see what services AWS offers to create a similar architecture.
Proposed implementation on AWS
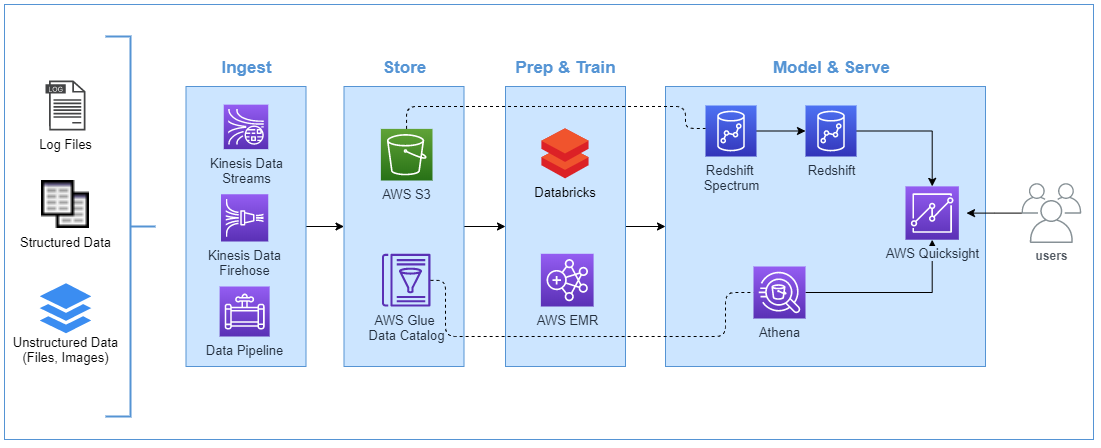
Ingest: For the data ingestion, three use-case specific services are part of this component. For real-time data ingestion, AWS Kinesis Data Streams provide massive throughput at scale. For near real-time, AWS Kinesis Firehose serves the purpose and for data ingestion at regular intervals in time, AWS Data Pipeline is a data workflow orchestration service that moves the data between different AWS compute and storage services including on-premise data sources.
Store: Nothing new here, AWS S3 is highly regarded as one of the best storage options in the public cloud to store any amounts of data with high level of durability, availability and low costs. For data discovery and metadata storage options, AWS Glue Data Catalog is used to create a metadata catalog. You can define crawlers to crawl multiple data stores and create or update one or more tables in the data catalog. It’s seamless integration with Amazon Athena makes it even a more powerful tool in the Data Analytics space.
Prep & Train: With AWS, you can also use Databricks for data preparation and training purposes. It provides a Unified Analytics Platform for massive scale data engineering and collaborative data science use-cases. Similar to Azure HDInsight, AWS offers EMR which provides cloud-native big data platform for processing huge amounts of data at scale. Tools like Apache Spark, Apache Hive, Apache HBase, Apache Flink, Presto etc. are part of this service.
Model & Serve: Finally, in the last component, AWS Redshift Spectrum runs on top of Redshift and provides peta-byte scale to execute data analytics queries without even loading the data into Redshift. It can directly query data from S3. Furthermore, for ad-hoc analysis on the data sources, you can use AWS Athena. For example, you can determine the quality of your dataset which is indeed very helpful in your downstream data warehouse or machine-learning models. For visualization, AWS Quicksight is a fast, cloud based business intelligence service that helps to create interactive dashboards with Data and Machine Learning insights.
For more details, refer to the following links to get more provider specific information about Big Data and Advanced Analytics solutions.
• Azure Architecture on Advanced Analytics
• Azure to AWS Services Comparison
Conclusion:
As per Gartner, AWS still has the highest market share within the public cloud services providers but we’ve seen Microsoft Azure catching up quickly over the years and the difference is getting less every passing year. Having said that, AWS and Microsoft compete very closely in the Big Data and Advanced Analytics space. The breadth and depth of the services offered by each provider enables its customers to realize the implementation of Advanced Analytics use-cases at scale.
If you’re planning to or already in a process to modernize your Data and Analytics workloads on one of these providers, do share your feedback below!
Happy Architecting!